
在国际范围内,对硅半导体的资料科学,制作工艺,有才能也有志愿继续的厂商可能只留下了Intel,Samsung,TSMC与Global Foundries。在近期或许在不久的将来,或许我国为了完结国际工厂的巨大转型,将接过半导体生产制作的旗号,使其愈加廉价,使其愈加缺少必要的盈余以支撑整个产业链的继续开展,维系也在完结这个职业。我继续悲观地维持在几年前的判断[3],根据硅的半导体工业不可或缺,也不再重要。谈核算
缘起于上世纪四十年代的冯诺依曼系统正在等待着最终一根稻草。至今处理器的规划者再也无法依照自身的理念决议自己的规划方向,当这些处理器的规划者不知道做什么适宜,而回身专心于Cache、内存与I/O通路时,根据冯诺依曼系统的传统处理器现实上现已完毕。把握用户场景与运用的厂商现在是处理器真实的规划主导者。定制化时代不再是多年之前的预判[4],而是已然降临,并操纵着处理器规划的方向。
硅半导体与传统处理器的停滞不前,不会完毕人类关于硅的依靠,在短期内尚无任何资料能够完全代替硅。运用关于硅的需求仍然清晰。在一分钟内,Youtube将至少接纳长达100个小时的视频文件[5];在Facebook上,每天有40亿次视频点击播映[6]。这些运用需求将经过网络,抵达各类效劳器,并从存储器中获取或许写入数据,进行着各类数据的处理。在核算、网络与存储这些根底架构中,硅半导体仍然占有主导地位。
奇特的半导体硅改变了人类前史的开展轨道,也简直走到了尽头。近半个世纪以来,硅一向有互补品,如砷化镓GaAs与氮化镓GaN,这些在大功率与高频范畴已有着严重运用的半导体资料无法代替硅,根据二硫化钼MoS2和碳纳米管CNT (Carbon Nanotube)的晶体管乃至能够将Gate Length做到1nm[7],可是仍然处于实验室阶段,用其代替硅只是停留在论文的纸面之上。至今硅工业的天花板制约了整个IT根底设施职业行进的脚步。
在核算范畴,被软银收买的ARM现已难以对x86处理器带来继续的压力。在手机处理器上取得了长足进步的苹果、高通、三星与华为,在近期难以在效劳器市场上对Intel带来实质性的应战。许多ARM效劳器在SPECInt的测验中声称已逐步接近了x86处理器,却在有意无意的疏忽着一个清楚明了的现实,这一代的效劳器,乃至是手机处理器,都不应该继续关注SPECInt与SPECfp这类单纯比拼核算功能的基准测验。
现在处理器的规划中心现已转向I/O与Memory Hierarchy通路的建设。在Intel的Broadwell-E处理器的Die Map[8]中,10个处理器微架构(Core)合在一起所占的份额现已不算太大,Memory Hierarchy与I/O占有了大多数的Die资源。
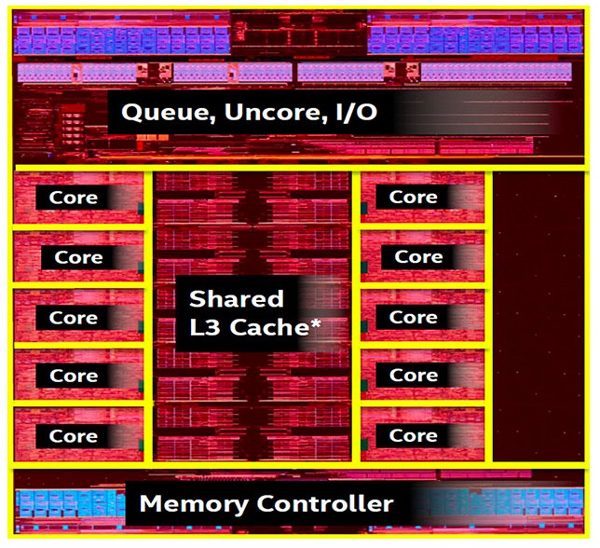
图12 Intel的Broadwell-E处理器的Die Map[8]
在一个处理器微架构中,运算单元所占的份额简直能够疏忽不计,在处理器微架构中,仍然是品种繁复,各类数据缓冲占有着主导方位。现实上,除了模仿器材以及与模仿器材强相关的芯片外,在多数芯片Die Map中,缓冲都占有着要害方位。迄今为止,核算范畴的多数运用对处理器的运用都是访存密集型。
处理器的规划初衷本是为核算效劳,可是在今天的许多运用场景中,处理器所承当更多的使命是经过各类I/O设备获取数据;这些数据在穿越Memory Hierarchy后抵达CPU的中心部件;CPU中心部件在准确核算着心跳的过程中,尽可能地快速处理这些数据,然后将其再次转发至远方。和密集核算相关的使命,现现已过各类硬件加快引擎,GPU或许专用ASIC完成。
咱们无法直面一个简略而令人懊丧的现实,在处理器运转着的各类协议栈的代码组成中,用于完成快速路径的代码可能不超越1%;99%以上的用于反常处理的代码,能够在超越99.9%以上的时间段内安然入眠,其存在只为等待着可能的反常呈现。
不是由于这些数不胜数的反常需求处理,或许咱们这个国际现已不再需求通用处理器了。从纯核算的角度上剖析,各类硬件加快引擎,GPU、FPGA或许专用ASIC,远胜今天的处理器,可是这些加快引擎在面临不计其数种反常时力不从心。在移动互联网厂商的数据中心中,处理器存在的最首要意图是对各类数据流进行剖析、拼装、打包后发往下一站。
在这些运用场景中,处理器存在的首要原因仍然不是其高效的报文转发才能,而是能够应对在报文处理过程中呈现的各类反常。在数据中心中,处理器存在的首要效果是能够相对高效地处理数据报文,一起还能对各类反常进行查漏补缺。不仅在核算范畴,在IT根底设施的网络与存储范畴,通用处理器的运用方法仍然如此。
能够对通用处理器带来应战的GPU,远景没有想象中乐观。从规划战略上看,GPU与通用处理器的最大差异在于对反常的处理。GPU专心极致核算,尽最大的可能提高TLP (Thread-Level Parallelism),而疏忽反常处理;通用处理器需求考虑反常状态的处理,以追求更大的适用性。
在不同规划战略的引导下,GPU走出了一条与通用处理器悬殊的路途。Nvidia的Pascal GP100由最多可达6个的一组GPC (Graphics Processing Clusters)构建;这些GPC共享同一个4096 KB的L2 Cache;经过8个512位的Memory Controller对外交流数据;运用高速的NVLink接口与其他GP100互联;最终经过PCIe 3.0总线与通用处理器进行衔接[9]。
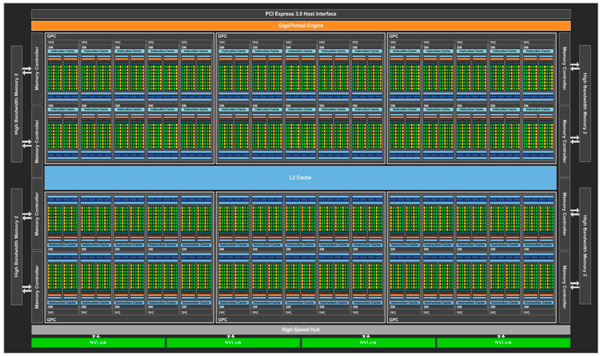
图13 Nvidia Pascal GP100 GPU组成结构[9]
在每一个GPC中,最多能够包容5个TPC (Texture Processing Clusters);每个TPC中集成两个SM (Streaming Multiprocessors);每一个SM包括64个CUDA和4个TU (Texture Unit)。其间最基本的CUDA中心和TU数目别离可达3840与个240个。GPU的Die Size可达610mm2,所能包容的晶体管数目可达153亿个[9]。
GPU与通用处理器,是规划者在面临有限的Die Size资源,做出的不同挑选,以适用于不同的运用场景。由数目繁复的运算单元所组成的GPU,其组成结构不比通用处理器杂乱,反而更为简略。可是这无法解释,Intel能够做出更为杂乱的通用处理器,却在高端GPU范畴上重复折戟沉沙;也无法解释,效劳器级处理器的规划难度超越手机处理器,Intel仍然百战百胜。
通用处理器需求处理各类已知与不知道的反常,在进行核算的一起,不断地处理各类分支跳转语句;随时预备应对各类中止事情;与此一起需求具有大规划的数据吞吐才能;也因此通用处理器需求一个规划庞大的通用操作系统。至今,核算已是通用处理器中的一个微小组成模块,通用处理器中最大的模块,是各类Cache和与其紧密联系在一起的Memory Hierarchy。
GPU聚焦的核算国际相对单纯;所处理的数据规整;数据间简直没有太多的依靠;不需求办理外部设备,不需求处理各类中止与反常,也不需求一个操作系统。从GPU的开展前史上,能够发现,GPU所处理的图画数据并不具有十分强的Locality特性。在GPU中,Cache存在的首要效果不是为了保存需求重复运用的数据,而是为了补偿GPU内部运算部件与外部DRAM之间的拜访推迟,然后没有如通用处理器那样的,杂乱程度令人拍案叫绝的Cache Hierarchy结构。
在GPU中,存在与通用处理器相似的流水线,Nvidia的GP100中的基本组成模块SM,自身就是也是一个流水线,这个流水线也被称为Graphics Pipeline,在不考虑光栅化处理的场景下,Graphics Pipeline也被称为Rendering Pipeline。
注:文章内容和图片均来源于网络,只起到信息的传递,不是用于商业,如有侵权请联系删除!



